
xAI Grok 4.1 update rolled out quietly across the Grok website, X app, and API access points earlier this month. But AI enthusiasts quickly noticed something different — the model felt sharper, smoother, and more “human” than its previous versions.
Within hours, benchmark charts, ranking screenshots, and side-by-side comparisons began circulating across Reddit, X, and tech forums. Users were both celebrating and scrutinizing the update, turning Grok 4.1 into one of the most talked-about AI stories of the week.
This article breaks down what’s new, what benchmarks reveal, and how the community is reacting, with visual placeholders that allow you to insert data screenshots directly into your article.
What’s New in Grok 4.1 Update
xAI claims Grok 4.1 is the most advanced and stable version of the model to date. User tests confirm this in several key categories.
1. Improved Conversational Tone & Emotional Intelligence
One of the most highly praised improvements appears in everyday conversations.
Grok 4.1 now:
- Responds with more empathy
- Understands emotional subtext better
- Provides more context-aware answers
- Avoids the sarcasm/flatness that older versions were known for
Users have shared examples where Grok 4.1 offers responses closer to human emotional awareness, especially during sensitive topics such as stress, grief, or personal decisions.
This shift marks a key step in xAI’s effort to make Grok not just powerful, but more approachable and relatable.
2. More Coherent Reasoning Mode
Grok’s “Thinking Mode” — designed for step-by-step reasoning — appears more structured and consistent.
User tests show:
- Fewer logic jumps
- Clearer breakdown of steps
- More consistent chain-of-thought patterns
The model still struggles occasionally with strict multi-step logic, but the improvement is noticeable when compared to earlier versions.
3. Slight Reduction in Hallucination Frequency
While not a dramatic change, third-party testing and user comparisons reveal that Grok 4.1 generates slightly fewer factual errors than previous versions.
Reported hallucination drop:
≈ 4.8% → 4.22%
This places Grok in a stronger reliability range, though still not as low as the most conservative LLMs on the market.
4. Stronger Creative Writing Output
Grok 4.1 has benefited from additional training in creative language tasks.
Users say:
- Stories feel more immersive.
- Character voices are more consistent.
- Metaphors and descriptive details improved.
- Writing flows naturally instead of abruptly.
This explains Grok 4.1’s strong performance in creative benchmarks, covered below.
Benchmark Performance: What the Data Shows
Benchmarks were the biggest driver of online debate, with screenshots widely shared across Reddit and X showing surprising results.
Below are the three essential benchmark visuals for which you requested placeholders.
1. Grok 4.1 Ranked #1 on LMArena (in Thinking Mode)
One of the most circulated screenshots shows Grok 4.1 achieving:
- 1483 Elo (Thinking Mode)
- 1465 Elo (Standard Mode)
This places it at or near the top of the leaderboard, surpassing strong competitors and even overtaking previous favorites like Gemini 2.5 Pro and Claude 3.5 Sonnet (depending on category).
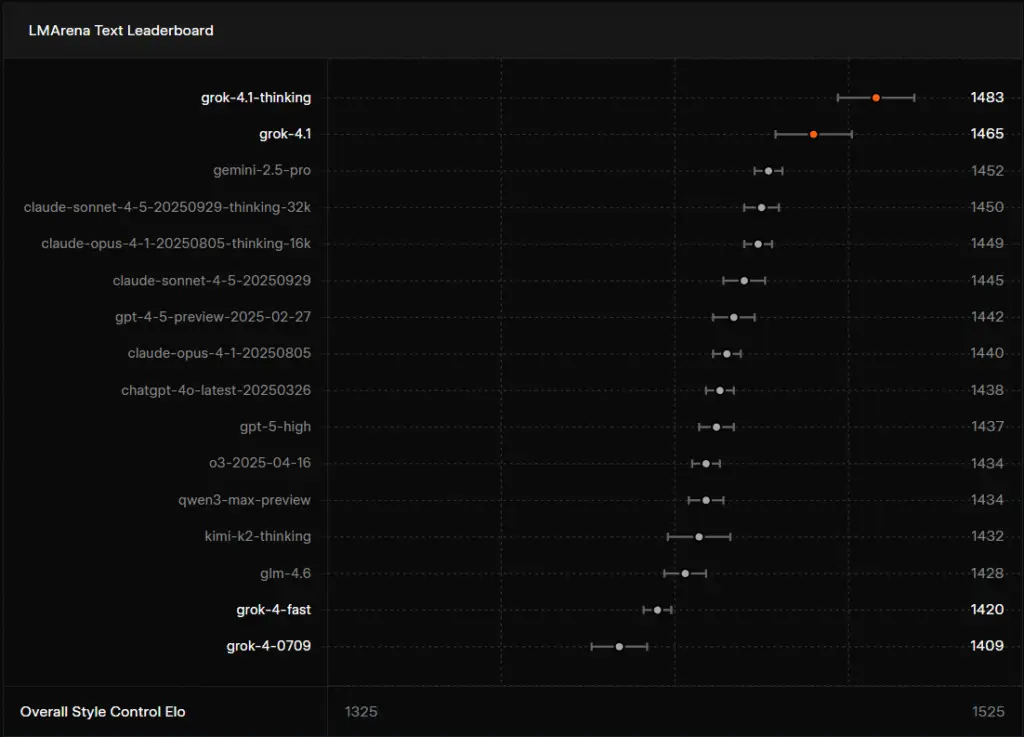
This was a surprising moment for the community, given how far Grok lagged behind other leading LLMs earlier this year.
2. Strong Scores in Creative Writing & EQ Benchmarks
Another widely shared chart shows Grok 4.1 performing strongly in:
- Creative Writing Benchmark v3
- EQ-Bench v3 (Emotional Intelligence)
These benchmarks measure:
- Empathy
- Narrative ability
- Tone consistency
- Realism in writing
Grok 4.1 showed clear improvements, which is consistent with the “more human” conversational tone users reported.
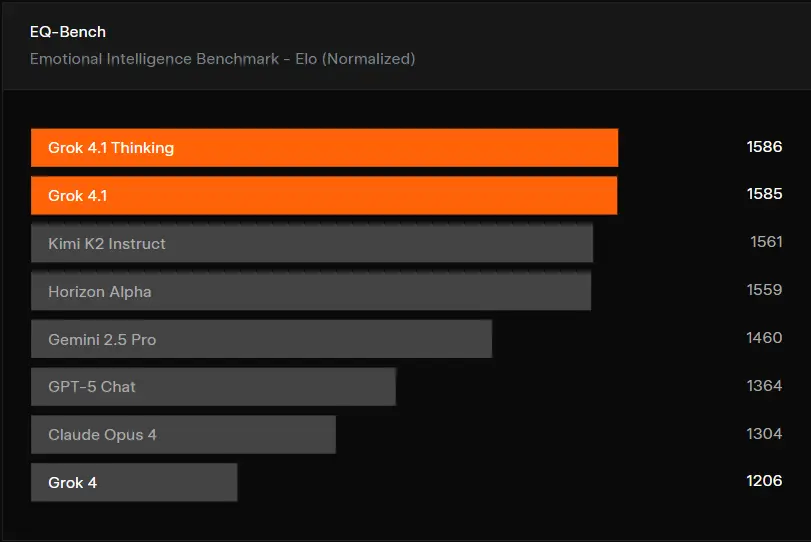
This visual evidence confirms that xAI has targeted improvements toward writing, storytelling, and human-like dialogue.
3. Hallucination Rate: Slight Improvement but Still Noticeable
A well-discussed chart circulating in AI communities shows a slight drop in hallucinations compared to earlier versions.
While the reduction is not drastic, it signals more controlled factual generation.
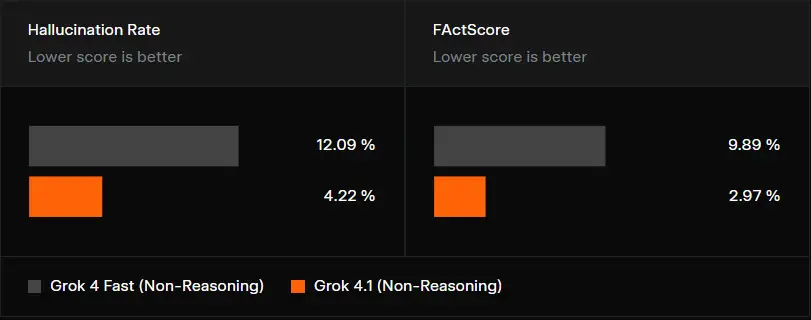
However, Grok still lags behind models known for conservative factual accuracy, and the occasional incorrect responses shared by users confirm that hallucinations remain present.
Community Reactions: What Reddit & X Users Say
The release has generated a mix of excitement and skepticism — a typical response to major AI version updates.
Below is a neutral summary of the strongest community sentiments.
Positive Reactions
1. “This is the first Grok version that feels premium.”
Users praised the conversational improvements, saying responses finally resemble those from top-tier models.
2. “Creative writing is insanely better.”
Writers shared examples of vivid stories, cleaner narratives, and more nuanced emotional expression.
3. “It beat Gemini and Claude in some benchmarks.”
This was one of the most exciting talking points — people didn’t expect Grok to rank this high so soon.
Critical Reactions
1. “Benchmarks look great, but real usage still has flaws.”
Many users claim that Grok 4.1 ranks high on Elo benchmarks, but it occasionally produces incorrect or inconsistent logic in practical tasks.
2. “Still makes factual mistakes in simple queries.”
Examples include wrong geographical facts, miscounting steps, or inconsistent interpretations.
3. “More sycophancy.”
Some users reported that Grok 4.1 was overly agreeable and avoided pushback.
Real-World Performance Tests
Across Reddit, X, and Discord groups, users shared hands-on results.
1. Coding
Mixed. Some improvements in explanation clarity, but logic errors still appear.
2. Math
Inconsistent. Sometimes perfect, sometimes flawed in multi-step reasoning.
3. Long-Form Writing
One of the strongest improvements — reports are overwhelmingly positive.
4. Roleplay & Persona Writing
Users say this is where Grok 4.1 truly shines, offering fluid, consistent, emotionally intelligent roleplay scenarios.
Final Verdict: Where Grok 4.1 Stands Today
Grok 4.1 is xAI’s most serious and competitive update to date.
It has clearly matured in:
- emotional intelligence
- conversational depth
- creative writing
- benchmark performance
And while it still shows weaknesses in:
- strict reasoning
- factual precision
- sycophancy
- consistency under complex queries
it has closed much of the gap between Grok and the industry leaders.